Collection接口见:Collection接口(List和Set)
HashMap
HashMap.java(@since 1.2)
直接看官方源码注释,写得很清楚
Hash table based implementation of the {@code Map} interface. This implementation provides all of the optional map operations, and permits {@code null} values and the {@code null} key. (The {@code HashMap} class is roughly equivalent to {@code Hashtable}, except that it is unsynchronized and permits nulls.) This class makes no guarantees as to the order of the map; in particular, it does not guarantee that the order will remain constant over time.
- 基于Map接口实现的哈希表
- 允许值为null的键值对(不同于HashTable)
- 线程不安全的(不同于HashTable)
- 除此之外功能与HashTable类似
This implementation provides constant-time performance for the basic operations ({@code get} and {@code put}), assuming the hash function disperses the elements properly among the buckets. Iteration over collection views requires time proportional to the “capacity” of the {@code HashMap} instance (the number of buckets) plus its size (the number of key-value mappings). Thus, it’s very important not to set the initial capacity too high (or the load factor too low) if iteration performance is important.
- 通过哈希方法将键值对正确的放置在对应的桶中
- 遍历所需的时间取决于实例的容量以及键值对数量
- 遍历时,最好不要将初始容量设的太高(或者负载因子设置的过低)
An instance of {@code HashMap} has two parameters that affect its performance: initial capacity and load factor. The capacity is the number of buckets in the hash table, and the initial capacity is simply the capacity at the time the hash table is created. The load factor is a measure of how full the hash table is allowed to get before its capacity is automatically increased. When the number of entries in the hash table exceeds the product of the load factor and the current capacity, the hash table is rehashed (that is, internal data structures are rebuilt) so that the hash table has approximately twice the number of buckets.
影响HashMap的两个比较重要的参数:initial capcity 和 load factor(默认0.75 in java8)
capacity:哈希表中桶的数量
load factor:键值对数 比上 桶数
随着键值对数量的增加,比值超过负载因子,HashMap就会进行rehashed操作扩容。
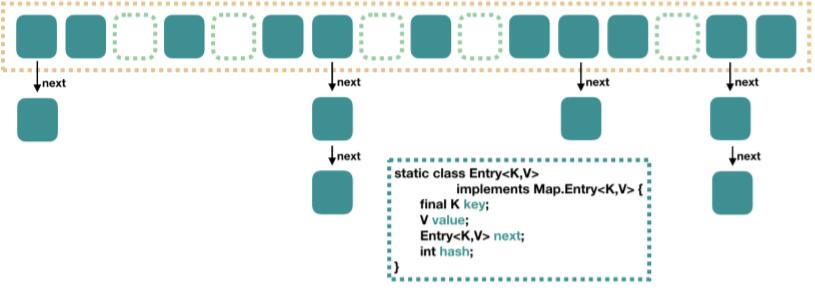
JAVA7中的HashMap结构
在Java7中,查找某元素时,根据hash值可以快速找到数组具体的下标,但后面的操作需要遍历一长串单链表才能找到目标值。时间复杂度取决于链表的长度,为$O(n)$.
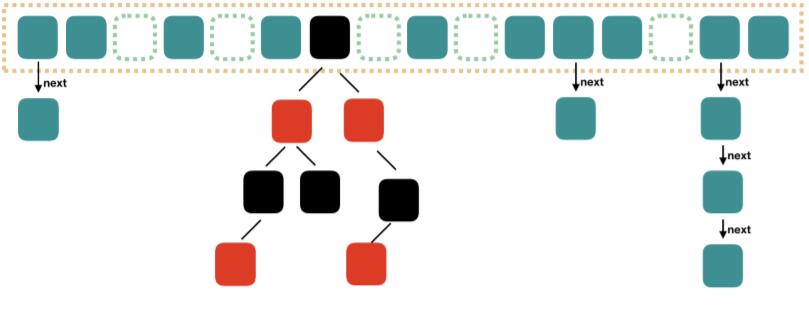
JAVA8中的HashMap结构
在Java7的基础上,当链表中的元素超过8个之后,将链表转换为红黑树,在这些位置查找时可以降低时间复杂度为$O(logn)$.
Tips:
- 在HashMap中,可以看成key为set集合:无序的不可重复的,key所在的类需要重写equals()和hashCode()
- 所有的value构成的集合是Collection,无序的,可以重复的。value所在的类需要重写equals()。
- 一对key-value构成一个entry,所有的entry构成的集合也是无序的,不可重复的
- 判断key相等的标准:两个key通过equals()方法返回true,hashCode值也相等。
- 判断value相等的标准:两个value通过equals()方法返回true。
LinkedHashMap
LinkedHashMap.java(@since 1.4)
Hash table and linked list implementation of the {@code Map} interface, with predictable iteration order. This implementation differs from {@code HashMap} in that it maintains a doubly-linked list running through all of its entries. This linked list defines the iteration ordering, which is normally the order in which keys were inserted into the map (insertion-order). Note that insertion order is not affected if a key is re-inserted into the map. (A key {@code k} is reinserted into a map {@code m} if {@code m.put(k, v)} is invoked when {@code m.containsKey(k)} would return {@code true} immediately prior to the invocation.)
LinkedHashMap 是 HashMap 的一个子类,保存了记录的插入顺序,在用 Iterator 遍历 LinkedHashMap时,先得到的记录肯定是先插入的,也可以在构造时带参数,按照访问次序排序。
TreeMap
A Red-Black tree based {@link NavigableMap} implementation. The map is sorted according to the {@linkplain Comparable natural ordering} of its keys, or by a {@link Comparator} provided at map creation time, depending on which constructor is used……Note that this implementation is not synchronized……
底层采用红黑树结构,因此数据会进行排序操作,默认为按键的升序排序。可以通过自然排序和定制排序实现。操作类似TreeSet的自然和定制排序,同样,由于要进行排序操作,所以key的类型必须要一致。
Hashtable
线程安全的、不可以存放null值,其余功能和HashMap类似。
遍历操作
1 |
|
forEach方法(lambda表达式)
1 | map.forEach((k,v) -> System.out.println( k + "-->" + v)); |
Set entrySet():返回所有key-value对构成的Set集合
1 | Set entrySet = map.entrySet(); |
Set keySet():返回所有key构成的Set集合
1 | Set keySet = map.keySet(); |
常见方法
添加、删除、修改操作
Object put(Object key,Object value):将指定key-value添加到(或修改)当前map对象中
void putAll(Map m):将m中的所有key-value对存放到当前map中
Object remove(Object key):移除指定key的key-value对,并返回value
void clear():清空当前map中的所有数据
元素查询的操作
Object get(Object key):获取指定key对应的value
boolean containsKey(Object key):是否包含指定的key
boolean containsValue(Object value):是否包含指定的value
int size():返回map中key-value对的个数
boolean isEmpty():判断当前map是否为空
boolean equals(Object obj):判断当前map和参数对象obj是否相等
元视图操作的方法
Set keySet():返回所有key构成的Set集合
Collection values():返回所有value构成的Collection集合
Set entrySet():返回所有key-value对构成的Set集合